검색결과 리스트
먹고살기에 해당되는 글 55건
- 2025.02.18 inode 감시
- 2014.03.21 공백제거 5
- 2011.08.10 window 오라클 삭제하는 방법(oracle 10g)
- 2011.08.10 Analytic Function
- 2011.08.10 SQL -- Analytic Function
글
#!/bin/bash
# 특정 파일시스템의 inode 사용율을 체크합니다.
check_inode_usage() {
local filesystem=$1
local usage=$(df -i | grep $filesystem | awk '{print $5}' | sed 's/%//')
echo "$filesystem inode 사용율: $usage%"
}
# 전체 파일시스템을 순회하며 inode 사용율이 80% 이상인 경우를 출력합니다.
for filesystem in $(df -i | awk 'NR>1 {print $1}')
do
usage=$(df -i | grep $filesystem | awk '{print $5}' | sed 's/%//')
if [ $usage -ge 80 ]; then
echo "$filesystem inode 사용율: $usage%"
fi
done
while IFS= read -r line; do
filesystem=$(echo $line | awk '{print $1}')
usage=$(echo $line | awk '{print $5}' | sed 's/%//')
if [[ "$usage" =~ ^[0-9]+$ ]] && [ "$usage" -ge 80 ]; then
echo "$filesystem inode 사용율: $usage%"
fi
done < <(df -i | awk 'NR>1')
설정
트랙백
댓글
글
sed -i -e 's/\r$//' install.sh
설정
트랙백
댓글
글
+오라클설치 만큼 중요한 삭제하기!!
삭제가 중요한이유는 삭제를 잘해야! 설치도 잘되기 때문이다. (뭐 당연한 말이지만;;)
보통 프로그램들은 '제어판-프로그램 추가/삭제' 한번으로 간단히 끝난다.
하지만!! 오라클의 경우에는 얘기가 조금 다르다.
프로그램도 지워야하고, 저장되어있는 DB도 지워야 하기때문이다.
그렇다고 겁먹을 필요는 없다.
정해진 순서를 따라 하면되니까
(길다고 훅훅 내려보지말고 천천히 따라하길바란다!)
우선! 순서를 간단하게 살펴보자.
1. 서비스중지
2. 오라클 설치해제
3. 레지스트리 정리
4. C:혹은 D: 오라클 폴더삭제
5. 리부팅
총 5단계면 끝난다.
의외로 간단하지 않은가?!
그럼 이제 본격 적으로 삭제를 실습해보자!
1.서비스중지
제어판 - 관리도구 - 서비스 - oracle 로 시작하는 서비스 중지하기 !

2. 오라클 설치해제
시작 - Oracle installation Products - Universal installer - 제품 설치 해제

↓↓↓

↓↓↓

↓↓↓

↓↓↓

3.레지스트리 정리!
시작 - 실행 - regedit
아래 사진 처럼 경로를 보고 oracle~ 로 시작하는 것들을 다 지운다!
↓↓↓
HKEY_LOCAL_MACHINE\SOFTWARE\ORACLE
HKEY_LOCAL_MACHINE\SOFTWARE\ODBC
HKEY_LOCAL_MACHINE\SYSTEM\CurrentControlSet\Services\Oracle~
HKEY_LOCAL_MACHINE\SYSTEM\CurrentControlSet\Services\EventLog\Application\Oracle~
HKEY_LOCAL_MACHINE\SYSTEM\ControlSet001\Services\Oracle~
HKEY_LOCAL_MACHINE\SYSTEM\ControlSet002\Services\Oracle~
HKEY_LOCAL_MACHINE\SYSTEM\CurrentControlSet\Services\Oracle~
↓↓↓

4. C:혹은 D: 오라클 폴더삭제
C:\oracle 삭제, C:\Program Files/oracle 삭제

↓↓↓

※ 만약 지울수 없다고 나온다면 리부팅을 먼저한다!
↓↓↓
시작프로그램에 바로가기도 지워주는 센스 !!!

5.리부팅!!!
+이것으로 삭제가 끝났다.
생각보다 쉽지않았는가! 단지 할일이 초큼 많을 뿐이다.
설치 할때 오류 없이 편히 하려면
이정도 수고쯤이야~
다들 좋은(?)삭제 했길바란다!!
++보너스!!! 삭제 잘됐나 확인하기 'ㅁ'//

[출처] window 오라클 삭제하는 방법(oracle 10g)|작성자 룰루루
'먹고살기 > Oracle' 카테고리의 다른 글
| Analytic Function (0) | 2011.08.10 |
|---|---|
| SQL -- Analytic Function (0) | 2011.08.10 |
| GROUP BY의 고급 응용 (0) | 2011.08.10 |
| DECODE와 CASE WHEN ... (0) | 2011.08.10 |
| Oracle case문 (0) | 2011.08.10 |
설정
트랙백
댓글
글
Analytic Function (분석 함수)
분석 함수는 Aggregate Function 의 계산을 지정하는 행 그룹을 기반으로 계산하여 각 그룹에 대해 여러 행을 반환 할 수 있는 Function 을 말합니다. 일반적으로 누적 계산, 집계 및 보고용 결과를 질의 할 때 유용하게 사용 할 수 있으며 복잡한 질의를 보다 간편하고 빠르게 실행 할 수 있게 도와 줍니다.
ex.
SQL> select empno, ename, sal, deptno, sum(sal) dept_tot
from emp ;
ERROR at line 1:
ORA-00937: not a single-group group function
위의 문장은 SUM 이라는 Aggregate Function ( Group Function ) 을 GROUP BY 절 없이 일반 컬럼들과 함께 사용하였기에 발생한 에러 입니다.
하지만 다음의 문장은 어떤가요?
SQL> select empno, ename, sal, deptno,
sum(sal) over(partition by deptno) dept_tot
from emp ;
|
EMPNO ENAME SAL DEPTNO DEPT_TOT ---------- ---------- ---------- ---------- ---------- 7782 CLARK 2450 10 8750 7839 KING 5000 10 8750 7934 MILLER 1300 10 8750 7566 JONES 2975 20 10875 7902 FORD 3000 20 10875 7876 ADAMS 1100 20 10875 7369 SMITH 800 20 10875 7788 SCOTT 3000 20 10875 7521 WARD 1250 30 9400 7844 TURNER 1500 30 9400 7499 ALLEN 1600 30 9400 7900 JAMES 950 30 9400 7698 BLAKE 2850 30 9400 7654 MARTIN 1250 30 9400 |
각 그룹당 동일한 Function 의 결과를 반복 출력하며 에러 없이 실행 가능 합니다.
만약 위와 같은 결과를 확인 하고자 했을 때 분석함수를 사용하지 않는다면 어떤 문장을 사용해야 할까요?
SQL> select a.empno, a.ename, a.sal, a.deptno, b.dept_tot
from emp a, ( select deptno, sum(sal) dept_tot
from emp
group by deptno ) b
where a.deptno = b.deptno ;
결과는 같게 나옵니다. 허나 불필요한 Sub-Query를 이용해야 하며 원본 집합인 EMP 테이블을 반복적으로 Access 하는 등 비효율적인 문장이 되어 버립니다.
분석함수는 원하는 결과를 가져다 주는 SQL 을 보다 쉽게 만들 수 있도록 도와주며 성능 역시 향상 시켜주므로 그 쓰임새를 잘 익혀둘 필요가 분명 존재 합니다.
분석 함수 정의
|
SQL> select empno, ename, sal, deptno, sum(sal) over(partition by deptno) dept_tot from emp ; |
분석 함수는 Aggregate Function 뒤에 Analytic Clause (OVER 절)을 통해 행 그룹의 정의를 지정하고 각 그룹당 결과 값을 반복하여 출력 합니다. 여기서 행 그룹의 범위를 WINDOW 라 부릅니다. 하나의 WINDOW 가 계산을 수행하는데 사용되는 행들의 집합을 결정하게 되며 PARTITION BY, ORDER BY, WINDOWING 을 통하여 조절하게 됩니다.
또한 분석 함수는 Join 문장, WHERE, GROUP BY, HAVING 등과 함께 쓰일 때 가장 마지막에 연산(집계)을 진행하며 SELECT 절과 ORDER BY 절에서만 사용이 가능 합니다.
매뉴얼 상의 문법을 먼저 확인하면 다음과 같습니다.
http://download.oracle.com/docs/cd/B19306_01/server.102/b14200/functions001.htm#i88893
analytic function :
analytic clause :

query partition clause :

order by clause :

windowing clause :

|
항상 그렇듯이 매뉴얼에 나와 있는 부분은 왠지 부담이 가는 것은 사실입니다. 하지만 가장 정확한 내용을 각 버전에 맞게 설명하는 것은 사실이니 부담이 되더라도 항상 매뉴얼을 함께 참조하는 습관은 함께 하시길 바랍니다. |
분석함수 사용 시 OVER 절의 사용법만 정확히 이해 하신다면 나머지는 Aggregate Function 들의 특징 몇 가지만 이해 하시면 됩니다. 우선은 OVER 절을 먼저 살펴보도록 하겠습니다.
PARTITION BY 절은 GROUP BY 절과 동일한 역할을 진행 합니다.
단, GROUP BY 절을 사용하지 않고 필요한 집합으로 (WINDOW) 행들을 그룹화 시킴.
ex.
SQL> select empno, ename, sal,
avg(sal) over( ) avg_sal
from emp ; <= 전체의 평균 급여
|
EMPNO ENAME SAL AVG_SAL ---------- ---------- ---------- ---------- 7369 SMITH 800 2073.21429 7499 ALLEN 1600 2073.21429 7521 WARD 1250 2073.21429 7566 JONES 2975 2073.21429 … |
SQL> select empno, ename, sal, deptno, job,
avg(sal) over(PARTITION BY deptno, job) avg_sal
from emp ; <= 부서별, 업무별 평균 급여
|
EMPNO ENAME SAL DEPTNO JOB AVG_SAL ---------- ---------- ---------- ---------- --------- ---------- 7934 MILLER 1300 10 CLERK 1300 7782 CLARK 2450 10 MANAGER 2450 7839 KING 5000 10 PRESIDENT 5000 7788 SCOTT 3000 20 ANALYST 3000 … |
SQL> select d.deptno, d.dname, e.ename, e.sal,
avg(e.sal) over(PARTITION BY d.deptno) avg_sal
from emp e, dept d
where d.deptno = e.deptno ; <= 조인 후 부서별 평균 급여
|
DEPTNO DNAME ENAME SAL AVG_SAL ---------- -------------- ---------- ---------- ---------- 10 ACCOUNTING CLARK 2450 2916.66667 10 ACCOUNTING KING 5000 2916.66667 10 ACCOUNTING MILLER 1300 2916.66667 20 RESEARCH JONES 2975 2175 20 RESEARCH FORD 3000 2175 … |
Partition by 절을 사용 함으로 GROUP BY 절 없이 다양한 GROUPING 집합의 집계 결과들을 함께 출력 할 수 있습니다.
ORDER BY 절은 Partition by 로 정의된 WINDOW 내에서의 행들의 정렬 순서를 정의 한다.
ex.
SQL> select empno, ename, sal, deptno,
row_number( ) over ( ORDER BY sal ASC ) rnum
from emp ; <= 전체 급여를 오름차순으로 정렬 했을 경우 Row Number
|
EMPNO ENAME SAL DEPTNO RNUM ---------- ---------- ---------- ---------- ---------- 7369 SMITH 800 20 1 7900 JAMES 950 30 2 7876 ADAMS 1100 20 3 7521 WARD 1250 30 4 … |
SQL> select empno, ename, sal, deptno,
row_number( ) over ( PARTITION BY deptno ORDER BY sal DESC ) rnum
from emp ; <= 부서별 급여를 내림차순으로 정렬 했을 경우 Row Number
|
EMPNO ENAME SAL DEPTNO RNUM ---------- ---------- ---------- ---------- ---------- 7839 KING 5000 10 1 7782 CLARK 2450 10 2 7934 MILLER 1300 10 3 7788 SCOTT 3000 20 1 7902 FORD 3000 20 2 … |
부서 번호가 바뀔 때 Row Number 는 새로 시작 되는 것을 확인 할 수 있습니다.
SQL> select empno, ename, sal, comm,
DENSE_RANK( ) over ( ORDER BY comm ASC ) rnum
from emp
where deptno = 30 ; <= NULL 값은 정렬 시 가장 큰 값으로 인식 (기본설정)
|
EMPNO ENAME SAL COMM RNUM ---------- ---------- ---------- ---------- ---------- 7844 TURNER 1500 0 1 7499 ALLEN 1600 300 2 7521 WARD 1250 500 3 7654 MARTIN 1250 1400 4 7900 JAMES 950 5 7698 BLAKE 2850 5 7782 CLARK 2450 5 |
SQL> select empno, ename, sal, comm,
DENSE_RANK( ) over ( ORDER BY comm ASC NULLS FIRST ) rnum
from emp
where deptno = 30 ; <= NULL 값을 가장 작은 값으로 설정
|
EMPNO ENAME SAL COMM RNUM ---------- ---------- ---------- ---------- ---------- 7900 JAMES 950 1 7698 BLAKE 2850 1 7844 TURNER 1500 0 2 7499 ALLEN 1600 300 3 7521 WARD 1250 500 4 7654 MARTIN 1250 1400 5 |
ORDER BY 절은 Partition by 에 의해 그룹화 된 행들의 정렬 순서를 결정하며 NULL 값을 가지고 있는 행이 있을 경우 NULL 에 대한 값을 FIRST, LAST 로 보낼 수 있도록 조절 가능 합니다.
RANK ( ), DENSE_RANK ( ), ROW_NUMBER ( ) 의 차이점
SQL> select empno, ename, deptno, sal,
rank( ) over ( PARTITION BY deptno ORDER BY sal DESC ) rank,
dense_rank( ) over ( PARTITION BY deptno ORDER BY sal DESC ) d_rank,
row_number( ) over ( PARTITION BY deptno ORDER BY sal DESC ) rnum
from emp
where deptno in (10,20) ;
|
EMPNO ENAME DEPTNO SAL RANK D_RANK RNUM ---------- ---------- ---------- ---------- ---------- ---------- ---------- 7839 KING 10 5000 1 1 1 7782 CLARK 10 2450 2 2 2 7934 MILLER 10 1300 3 3 3 7788 SCOTT 20 3000 1 1 1 7902 FORD 20 3000 1 1 2 7566 JONES 20 2975 3 2 3 7876 ADAMS 20 1100 4 3 4 7369 SMITH 20 800 5 4 5 |
현재 결과는 부서별 급여를 기준으로 내림차순으로 정렬 하였을 때 순번을 보여 준다.
이때 RANK 는 동등 순위 발생 시 중복된 값만큼 증가시킨 3번이 다음 번호로 확인되며
DENSE_RANK 는 동등 순위 번호는 같게 나오고 그 다음 순위를 2번으로 보여 준다.
즉, 중복된 값만큼의 증가치는 없다는 것이며 ROW_NUMBER 는 동등 순위 자체를 인식하지 않고 매번 증가되는 번호를 부여 한다.
WINDOWING 절은 일부 Aggregate Function 과 함께 쓰일 수 있으며 행들의 그룹을 물리적, 논리적으로 조절하여 Function 이 적용될 WINDOW 를 정의 합니다.
즉, PARTITON BY 절은 컬럼에 같은 값을 기준으로만 그룹화를 시키나 WINDOWING 절은 ROWS 와 RANGE 를 이용하여 하나의 WINDOW를 결정하는 범위를 보다 자유롭게 조정할 수 있습니다.
ROWS (물리적인 단위 결정)
SQL> select empno, ename, sal,
sum(sal) over ( ORDER BY empno
ROWS BETWEEN UNBOUNDED PRECEDING AND
CURRENT ROW ) sum_sal
from emp
where deptno in (10,20) ;
|
EMPNO ENAME SAL SUM_SAL ---------- ---------- ---------- ---------- 7369 SMITH 800 800 7566 JONES 2975 3775 <= 800 + 2975 7782 CLARK 2450 6225 <= 3775 + 2450 7788 SCOTT 3000 9225 <= 6225 + 3000 7839 KING 5000 14225 <= 9225 + 5000 7876 ADAMS 1100 15325 <= 14225 + 1100 7902 FORD 3000 18325 <= 15325 + 3000 7934 MILLER 1300 19625 <= 18325 + 1300 |
ROWS 는 WINDOW의 범위를 정의할 때 물리적인 행을 지정 하는 부분입니다. 어떤 행에서 시작해서 어떤 행 까지가 하나의 WINDOW 영역으로 정의 할지 범위를 BETWEEN 을 통하여 정의 할 수 있습니다.
UNBOUNDED PRECEDING 는 첫 번째 행을 가리키며 UNBOUNDED FOLLOWING 은 마지막 행을 의미 합니다. CURRENT ROW 는 현재 행을 의미합니다.
그럼 위의 결과는 empno 순으로 오름차순 정렬한 집합에서 첫 번째 행부터 현재 행까지의 SUM(sal) 을 계산하는 누적 집계를 보여 줍니다.
이는 다음의 문장을 실행해도 동일한 결과를 보여 줍니다.
SQL> select empno, ename, sal,
sum(sal) over ( ORDER BY empno
ROWS UNBOUNDED PRECEDING ) sum_sal
-- 또는 sum(sal) over ( ORDER BY empno )
from emp where deptno in (10,20) ;
즉, BETWEEN 을 사용하지 않고 시작되는 행만을 지정하면 종료 행은 CURRENT ROW 가 지정 되게 됩니다.
그렇다면 BETWEEN UNBOUNDED PRECEDING AND UNBOUNDED FOLLOWING 을 사용하면 어떨까요? 첫 번째 행부터 마지막 행까지를 하나의 WINDOW 로 정의 할 수 있게 됩니다.
SQL> select empno, ename, sal,
sum(sal) over ( ORDER BY empno
ROWS BETWEEN UNBOUNDED PRECEDING AND
UNBOUNDED FOLLOWING ) sum_sal
from emp
where deptno in (10,20) ;
|
EMPNO ENAME SAL SUM_SAL ---------- ---------- ---------- ---------- 7369 SMITH 800 19625 7566 JONES 2975 19625 7782 CLARK 2450 19625 7788 SCOTT 3000 19625 7839 KING 5000 19625 7876 ADAMS 1100 19625 7902 FORD 3000 19625 7934 MILLER 1300 19625 |
PARTITION BY 절을 사용하여 동일한 VALUE 를 기반으로 하는 WINDOW 영역을 그대로 사용할 경우에는 WINDOWING 절은 사용상 의미가 없습니다. WINDOWING 절은 PARTITION BY 만으로 그룹화를 시키는 것이 아닌 좀더 세밀한 조정이 필요할 때 사용 합니다.
ROWS 는 물리적인 행을 기반으로 그룹화가 가능 합니다.
SQL> select empno, ename, sal,
sum(sal) over ( ORDER BY empno
ROWS BETWEEN 1 PRECEDING AND
CURRENT ROW ) sum_sal
from emp
where deptno in (10,20) ;
|
EMPNO ENAME SAL SUM_SAL ---------- ---------- ---------- ---------- 7369 SMITH 800 800 7566 JONES 2975 3775 <= 800 + 2975 7782 CLARK 2450 5425 <= 2975 + 2450 7788 SCOTT 3000 5450 <= 2450 + 3000 7839 KING 5000 8000 <= 3000 + 5000 7876 ADAMS 1100 6100 <= 5000 + 1100 7902 FORD 3000 4100 <= 1100 + 3000 7934 MILLER 1300 4300 <= 3000 + 1300 |
시작 행을 이전 행 ( 1 PRECEDING ) 으로 설정 하였으므로 현재 행과 이전 행만의 합계를 구하는 문장이 됩니다.
RANGE 는 논리적인 값을 근거로 WINDOW 범위를 설정 가능하게 합니다.
SQL> select ename, to_char(hiredate,'YYYY/MM/DD') hiredate, sal,
sum(sal) over ( ORDER BY hiredate
RANGE BETWEEN INTERVAL '3' MONTH PRECEDING
AND INTERVAL '3' MONTH FOLLOWING ) sum_sal
from emp
where deptno in (10,20) ;
|
ENAME HIREDATE SAL SUM_SAL ---------- ---------- ---------- ---------- SMITH 1980/12/17 800 800 <= 전후 3개월에 해당되는 값 없음 JONES 1981/04/02 2975 5425 <= 2975 + 2450 (04/02 ~ 06/09) CLARK 1981/06/09 2450 5425 <= 2975 + 2450 (04/02 ~ 06/09) KING 1981/11/17 5000 9300 <= 5000 + 3000 + 1300 (11/17 ~ 01/23) FORD 1981/12/03 3000 9300 <= 5000 + 3000 + 1300 (11/17 ~ 01/23) MILLER 1982/01/23 1300 9300 <= 5000 + 3000 + 1300 (11/17 ~ 01/23) SCOTT 1987/04/19 3000 4100 <= 3000 + 1100 (04/19 ~ 05/23) ADAMS 1987/05/23 1100 4100 <= 3000 + 1100 (04/19 ~ 05/23) |
입사 일자를 기준으로 정렬을 하였을 경우 현재 행이 가지고 있는 입사일자 전후로 3개월씩, 6개월 사이의 합계를 구하게 됩니다. RANGE 는 이렇게 논리적인 평가를 통하여 시작 행과 종료 행을 지정하게 합니다.
분석함수 종류 ( v10g )
분석함수의 종류는 다음과 같습니다. ( * 가 있는 것은 WINDOWING 절 사용 가능 )
각각의 링크를 통해서 매뉴얼을 참고 할 수 있습니다.
FIRST / LAST
각 WINDOW 영역에서 FIRST/LAST 행의 하나의 행만을 추출 하려는 경우 사용 가능.
ORDER BY 를 이용하여 WINDOW 내의 정렬을 진행하고 DENSE_RANK FIRST/LAST 로 그들 중 하나의 행을 선택할 수 있다. 이때 동일한 ranking 을 가지고 있는 집합들 중 Aggregate Function 의 결과를 보여 준다.
ex. 급여를 가장 많이 받는 사원과 가장 적게 받는 사원의 이름
SQL> select min(ename) keep ( dense_rank FIRST order by sal desc ) max_ename ,
min(ename) keep ( dense_rank LAST order by sal desc ) min_ename
from emp ;
|
MAX_ENAME MIN_ENAME ---------- ---------- KING SMITH |
ex. 부서별 급여를 가장 많이, 적게 받는 사원들의 이름
SQL> select deptno,
min(ename) keep ( dense_rank FIRST order by sal desc ) max_ename ,
min(ename) keep ( dense_rank LAST order by sal desc ) min_ename
from emp
group by deptno ;
|
DEPTNO MAX_ENAME MIN_ENAME ---------- ---------- ---------- 10 KING MILLER 20 FORD SMITH 30 BLAKE JAMES |
NTILE
분석용 Function 이며 WINDOW 그룹의 행을 정렬 후 지정한 개수의 범위(등급)으로 나눈 후 각 값이 가지고 있는 등급 값을 보여준다.
ex) 사원들의 급여를 많이 받는 순서대로 5개의 등급으로 나눠 표시
SQL> select empno, ename, sal,
NTILE (5) over ( order by sal desc ) grade
from emp ;
|
EMPNO ENAME SAL GRADE ---------- ---------- ---------- ---------- 7839 KING 5000 1 7902 FORD 3000 1 7788 SCOTT 3000 1 7566 JONES 2975 2 7698 BLAKE 2850 2 7782 CLARK 2450 2 7499 ALLEN 1600 3 7844 TURNER 1500 3 7934 MILLER 1300 3 7521 WARD 1250 4 7654 MARTIN 1250 4 7876 ADAMS 1100 4 7900 JAMES 950 5 7369 SMITH 800 5 |
CUME_DIST (cumulative distribution) / PERCENT_RANK
둘 모두 계산식에 차이가 있으나 WINDOW 그룹 내에서 누적 분포를 계산할 때 사용 가능.
값의 범위는 0 ~ 1 까지 사용되며 PERCENT_RANK 는 항상 시작 값이 0 부터 시작 됨.
ex. 급여를 내림차순 기준으로 정렬 하였을 경우 각 사원의 누적 분포를 계산
SQL> select ename, sal,
round ( PERCENT_RANK ( ) over ( order by sal desc ),2) as per_rank,
round ( CUME_DIST( ) over ( order by sal desc ),2) as cume_dist,
RANK( ) over ( order by sal desc ) as rank,
ROW_NUMBER ( ) over ( order by sal desc ) as row_num
from emp ;
|
ENAME SAL PER_RANK CUME_DIST RANK ROW_NUM ---------- ---------- ---------- ---------- ---------- ---------- KING 5000 0 .07 1 1 FORD 3000 .08 .21 2 2 SCOTT 3000 .08 .21 2 3 JONES 2975 .23 .29 4 4 BLAKE 2850 .31 .36 5 5 CLARK 2450 .38 .43 6 6 ALLEN 1600 .46 .5 7 7 TURNER 1500 .54 .57 8 8 MILLER 1300 .62 .64 9 9 WARD 1250 .69 .79 10 10 MARTIN 1250 .69 .79 10 11 ADAMS 1100 .85 .86 12 12 JAMES 950 .92 .93 13 13 SMITH 800 1 1 14 14 |
PERCENT_RANK :( RANK - 1) / (COUNT(*) - 1)
CUME_DIST : ( RANK or ROW_NUMBER ) / COUNT(*)
(동등 순위의 RANK 발생 시 해당 RANK 의 마지막 ROW_NUMBER 사용)
SQL> select round( (1-1)/(14-1),2) per ,round( 1 / 14 ,2) cume from dual union all
select round( (2-1)/(14-1),2) ,round( 3 / 14 ,2) from dual union all -- row_num 사용 됨
select round( (2-1)/(14-1),2) ,round( 3 / 14 ,2) from dual union all -- row_num 사용 됨
select round( (4-1)/(14-1),2) ,round( 4 / 14 ,2) from dual union all
select round( (5-1)/(14-1),2) ,round( 5 / 14 ,2) from dual ;
|
PER CUME ---------- ---------- 0 .07 .08 .21 .08 .21 .23 .29 .31 .36 |
PERCENTILE_CONT / PERCENTILE_DISC
cume_dist, percent_rank 의 결과가 누적 분포도를 계산 한다면 PERCENTILE_CONT, PERCENTILE_DISC 는 분포도 값(지정되는 백분율)을 역으로 계산하여 실제의 값을 가져온다.
ex. 30번 부서번호를 가지고 있는 사원들을 급여를 기준으로 내림차순 정렬
SQL> select empno, ename, sal, deptno,
round( cume_dist ( ) over ( order by sal desc ),2) as cume_dist
from emp
where deptno = 30 ;
|
EMPNO ENAME SAL DEPTNO CUME_DIST ---------- ---------- ---------- ---------- ---------- 7698 BLAKE 2850 30 .17 7499 ALLEN 1600 30 .33 7844 TURNER 1500 30 .5 7521 WARD 1250 30 .83 7654 MARTIN 1250 30 .83 7900 JAMES 950 30 1 |
위의 결과에서 1500 의 급여가 전체 WINDOW 중의 50% 범위에 해당 하는 것을 확인
ex. 30번 부서번호를 가지고 있는 사원들 중 급여를 기준으로 내림차순 정렬을 하였을 때 50% 범위에 해당하는 급여는 얼마인가?
SQL> select PERCENTILE_CONT(0.5) within group ( order by sal desc ) as CONT ,
PERCENTILE_DISC(0.5) within group ( order by sal desc ) as DISC
from emp
where deptno = 30 ;
|
CONT DISC ---------- ---------- 1375 1500 |
PERCENTILE_CONT 는 선형 보간법을 이용하여 평균에 근거하는 결과를 보여주므로 실제의 값을 보여주는 PERCENTILE_DISC 보다는 정확한 값을 보여주지는 않을 수 있다.
보다 자세한 계산 공식은 매뉴얼 참고 가능 (MEDIAN 함수도 같은 결과 확인 가능하다.)
SQL> select MEDIAN(sal)
from emp
where deptno = 30 ;
|
MEDIAN(SAL) ----------- 1375 |
MEDIAN은 PERCENTILE_CONT(0.5) 와 같은 결과
Hypothetical Functions
가정에 근거하여 각 함수에 맞는 값을 확인 가능.
ex. 급여가 2000 이라면 각각 순위 및 백분율은 얼마인가?
SQL> select RANK (2000) WITHIN GROUP ( order by sal desc ) rank,
DENSE_RANK (2000) WITHIN GROUP ( order by sal desc ) dense_rank,
CUME_DIST (2000) WITHIN GROUP ( order by sal desc ) cume_dist,
PERCENT_RANK (2000) WITHIN GROUP ( order by sal desc ) per_rank
from emp ;
|
RANK DENSE_RANK CUME_DIST PER_RANK ---------- ---------- ---------- ---------- 7 6 .466666667 .428571429 |
FIRST_VALUE / LAST_VALUE
FIRST / LAST 와 비슷하게 WINDOW 내의 처음과 마지막 행의 값을 가져 올 수 있으며 WINDOWING 절을 지정하여 원하는 WINDOW 의 정의가 가능하다. 또한 NULL 을 제외 시키고 작업 가능 (FIRST / LAST 는 WINDOWING 절 사용이 불가능하며 NULL 이 포함되어 계산 됨)
SQL> select ename, sal, comm,
FIRST_VALUE (comm IGNORE NULLS)
OVER ( order by comm desc
rows between unbounded preceding and unbounded following ) fv_c1 ,
FIRST_VALUE (comm)
OVER ( order by comm desc
rows between unbounded preceding and unbounded following ) fv_c2 ,
FIRST_VALUE (comm IGNORE NULLS)
OVER ( order by comm desc ) fv_c3 ,
LAST_VALUE (comm IGNORE NULLS)
OVER ( order by comm desc
rows between unbounded preceding and unbounded following ) lv
from emp
where deptno = 30 ;
|
ENAME SAL COMM FV_C1 FV_C2 FV_C3 LV ---------- ---------- ---------- ---------- ---------- ---------- ---------- BLAKE 2850 1400 0 JAMES 950 1400 0 MARTIN 1250 1400 1400 1400 0 WARD 1250 500 1400 1400 0 ALLEN 1600 300 1400 1400 0 TURNER 1500 0 1400 1400 0 |
우선 검색된 6개 행의 COMM 컬럼 값을 확인. NULL 값이 2개 존재하며 0 ~ 1400 범위
OVER 절의 ORDER BY 를 이용하여 comm 을 기준으로 내림차순 정렬 진행 함. 단 ROWS 를 사용하여 window 의 범위는 전체 범위로 설정 된 컬럼이 있으며 FV_C3 는 WINDOWING 절이 생략되었으므로 첫 번째 행부터 현재 행까지 만의 범위 안에서 계산.
이렇게 FIRST_VALUE 와 LAST_VALUE 는 ROWS / RANGE 를 이용하여 WINDOW 를 직접 조절할 수 있다는 특징이 있습니다. 때문에 FIRST_VALUE / LAST_VALUE 사용 시 인라인 뷰를 사용해서 어떤 행이 첫 번째 행으로 하느냐를 조절할 필요도 존재.
자세한 사항은 매뉴얼을 참고
LEAD / LAG
지정된 개수의 이전, 이후 행의 값 가져오기. WINDOWING 절을 지정하지 못하며 NULL 값을 대체하는 값을 지정할 수 있음. (NVL 불필요)
ex. 30번 부서의 사원을 이름순으로 정렬하여 검색하며 이전,다음 행의 급여를 함께 표시
SQL> select empno, ename, sal,
LAG (sal,1,0) over ( order by ename ) prev_sal,
LEAD (sal,1,0) over ( order by ename ) next_sal
from emp where deptno = 30 ;
|
EMPNO ENAME SAL PREV_SAL NEXT_SAL ---------- ---------- ---------- ---------- ---------- 7499 ALLEN 1600 0 2850 7698 BLAKE 2850 1600 950 7900 JAMES 950 2850 1250 7654 MARTIN 1250 950 1500 7844 TURNER 1500 1250 1250 7521 WARD 1250 1500 0 |
RATIO_TO_REPORT
WINDOW 영역의 합계 내에서 현재 값이 차지하는 백분율. 별도의 WINDOWING 절을 설정하는 것은 불가능 함
ex. 사원 정보를 출력하면서 부서별 급여의 합계 중 해당 사원이 받는 급여의 백분율을 표시하고 부서별 급여의 합계도 함께 출력
SQL> break on deptno skip 1
SQL> compute sum label 'total' of sal on deptno
SQL> select deptno, ename,
round ( RATIO_TO_REPORT (sal) over ( partition by deptno ) , 2) ratio ,
sal
from emp ;
SQL> clear compute
SQL> clear break
|
DEPTNO ENAME RATIO SAL ---------- ---------- ---------- ---------- 10 CLARK .28 2450 KING .57 5000 MILLER .15 1300 ********** ---------- total 8750 20 JONES .27 2975 FORD .28 3000 ADAMS .1 1100 SMITH .07 800 SCOTT .28 3000 ********** ---------- total 10875 30 WARD .13 1250 TURNER .16 1500 ALLEN .17 1600 JAMES .1 950 BLAKE .3 2850 MARTIN .13 1250 ********** ---------- total 9400 |
sqlplus 의 몇몇 계산 명령어를 이용하면 원하는 결과를 보다 쉽게 가져 올 수 있습니다.
'먹고살기 > Oracle' 카테고리의 다른 글
| window 오라클 삭제하는 방법(oracle 10g) (0) | 2011.08.10 |
|---|---|
| SQL -- Analytic Function (0) | 2011.08.10 |
| GROUP BY의 고급 응용 (0) | 2011.08.10 |
| DECODE와 CASE WHEN ... (0) | 2011.08.10 |
| Oracle case문 (0) | 2011.08.10 |
설정
트랙백
댓글
글
○ Analytic Function
1. 정의
① 쿼리를 수행하는 구문 중에 가장 마지막에 실행된다. (order by 보다는 먼저 실행)
② 쿼리 구문을 수행하고 2차로 값을 가공한다.
2. 구문
|
select column_name, column_name over([partition by column_name], [order by column_nae, ... ]) from table; |
3. 누적합을 구하는 Analytic Function
|
select deptno, empno, ename, sal, sum(sal) over (partition by deptno order by sal) as dept_avg_sal : deptno별 누적 sal을 구하고 sal로 order by 하는데 같은 값의 row가 있으면 제대로 된 값이 안나올 수 있으므로 order에 구분할 컬럼을 더 해준다. select deptno, empno, ename, sal, sum(sal) over (partition by deptno order by sal, deptno) as dept_avg_sal
|
4. rank를 구하는 Analytic Function
① rank() : 순서를 정하는데 같은 값은 똑같은 순서로 정하고, 다음 순번은 없앤다. (1,2,2,4)
② dense_rank() : 다음 순번을 없애니 않는다. (1,2,2,3)
③ row_number() : 같은 값이라도 위치나 이름에 따라 순번을 정한다. (1,2,3,4)
|
select deptno, empno, ename, sal, rank() over(order by sal) "Rank", >>
select deptno, empno, ename, sal, rank() over(partition by deptno >>
|

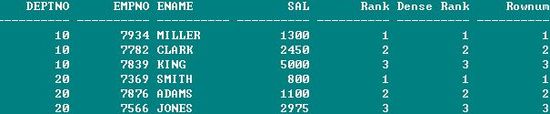
5. Moving Aggregates
|
select empno, sal, avg(sal) over (order by sal, empno) as ret1, --- 누적된 row의 평균 --- 자신을 포함한 위의 2 row의 평균 avg(sal) over (order by sal, empno rows between current row and 2 fllowing) as ret3 -- 자신을 포함한 밑의 2 row의 평균 >>
|
6. LAG , LEAD
① 자신의 row를 기준으로 위와 아래의 row
② example
|
select empno, ename, sal, lag(sal, 1, 0) over (order by sal) as prevsal : 현재 row의 1칸 위의 sal, 처음의 row는 위에 값이 없을 때, null을 return하므로 숫자를 넣을 수 있다. select empno, ename, sal, lead(sal, 1, 0) over (order by sal) as prevsal from emp; : 현재 row의 1칸 밑의 sal, 마지막 row는 밑에 값이 없을 때, null을 return하므로 숫자를 넣을 수 있다. |
7. First Value , Last Value
① 조건의 처음의 값과 마지막 값을 return
② Last Value는 버그가 발생 이에 관한 자료 참고
http://blog.naver.com/gseducation?Redirect=Log&logNo=20095625332
- last_value 대신 first_value를 사용하여 last_value의 결과값을 구할 수 있다.
|
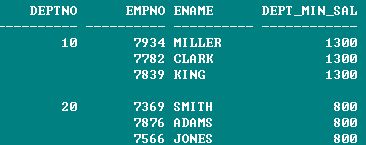
select deptno, empno, ename, first_value(sal) over(partition by deptno >>
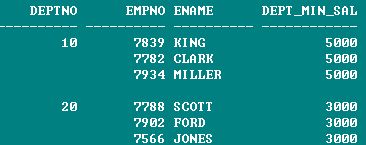
select deptno, empno, ename, first_value(sal) over(partition by deptno : last_value대신 first_value에서 order by의 desc를 사용하여 구할 수 있다. >>
[출처] SQL -- Analytic Function|작성자 도도리 |
'먹고살기 > Oracle' 카테고리의 다른 글
| window 오라클 삭제하는 방법(oracle 10g) (0) | 2011.08.10 |
|---|---|
| Analytic Function (0) | 2011.08.10 |
| GROUP BY의 고급 응용 (0) | 2011.08.10 |
| DECODE와 CASE WHEN ... (0) | 2011.08.10 |
| Oracle case문 (0) | 2011.08.10 |
RECENT COMMENT