검색결과 리스트
먹고살기/Oracle에 해당되는 글 50건
- 2011.04.29 SQL _ HAVING_2
- 2011.04.29 SQL _ CASE식
- 2011.04.25 [Oracle] ROWNUM 사용 시 주의
- 2011.04.22 오라클 데이터 타입
- 2011.04.22 오라클 DECODE
글
아래 테이블은 소방대원의 상태를 나타내는 표이다. 팀 전원이 대기 상태일 때만 출동이 가능하다.
출동명령을 내릴 수 있는 팀을 찾아보자.
Teams
|
member |
team_id |
status |
|
죠 |
1 |
대기 |
|
켄 |
1 |
출동중 |
|
미크 |
1 |
대기 |
|
카렌 |
2 |
출동중 |
|
키스 |
2 |
휴가 |
|
죤 |
3 |
대기 |
|
하트 |
3 |
대기 |
|
딕 |
3 |
대기 |
|
베스 |
4 |
대기 |
|
알렌 |
5 |
출동중 |
|
로버트 |
5 |
휴가 |
|
마크 |
5 |
대기 |
「모든 멤버의 상태가 "대기중"이다」라는 조건은 전칭양화이므로 NOT EXISTS를 사용하면 된다.
|
SELECT team_id, member
--결과-- TEAM_ID MEMBER |
이것은 전칭양화와 존재양화간의 동치변환을 이용한 것이다.
「모든 멤버의 상태가 대기중이다」
= 「대기중이지 않은 멤버가 한명도 존재하지 않는다」
이 쿼리는 퍼포먼스면에서 뛰어나고 구체적인 팀멤버도 표시가능하다는 장점이 있다. 하지만 이중부정을 사용하기 때문에 직감적으로 알기 어려운 쿼리이기도 하다.
HAVING구를 사용하면 다음과 같이 간단하게 표현할 수 있다.
|
--전칭문을 집합으로 표현 ① SELECT team_id THEN 1 ELSE 0 END);
----전칭문을 집합으로 표현 ② SELECT team_id
--결과-- team_id ------- 3 4 |
이번에는 출동가능멤버를 일람하는 쿼리를 만들어보자
|
SELECT team_id,
--결과-- TEAM_ID STATUS |
Materials
|
center |
receive_date |
material |
|
서울 |
2007-4-01 |
주석 |
|
서울 |
2007-4-12 |
아연 |
|
서울 |
2007-5-17 |
알루미늄 |
|
서울 |
2007-5-20 |
아연 |
|
부산 |
2007-4-20 |
동 |
|
부산 |
2007-4-22 |
니켈 |
|
부산 |
2007-4-29 |
납 |
|
대구 |
2007-3-15 |
티탄 |
|
대구 |
2007-4-01 |
탄소강 |
|
대구 |
2007-4-24 |
탄소강 |
|
대구 |
2007-5-02 |
마그네슘 |
|
대구 |
2007-5-10 |
티탄 |
|
인천 |
200-5-10 |
아연 |
|
인천 |
2007-5-28 |
주석 |
위의 테이블에서 자원이 중복되어 있는 거점을 찾는 쿼리를 만들어보자.
|
--자원이 중복된 거점 선택 SELECT center
--결과-- CENTER
--거점마다 중복여부 일람표시 SELECT center,
--결과-- CENTER STATUS
--중복이 있는 집합: EXISTS이용 SELECT center, material
--결과-- CENTER MATERIAL |
위테이블에서 원산국을 추가시킨 테이블을 이용해 (자원,원산국)의 2열로 봤을 때 중복되어 있는 거점을 선택하는 쿼리를 만들어보자.
Materials2
|
center |
receive_date |
material |
orgland |
|
서울 |
2007-04-01 |
주석 |
칠레 |
|
서울 |
2007-04-12 |
아연 |
타이 |
|
서울 |
2007-05-17 |
알루미늄 |
브라질 |
|
서울 |
2007-05-20 |
아연 |
타이 |
|
부산 |
2007-04-20 |
동 |
호주 |
|
부산 |
2007-04-22 |
니켈 |
남아프리카 |
|
부산 |
2007-04-29 |
납 |
인도 |
|
대구 |
2007-03-15 |
티탄 |
볼리비아 |
|
대구 |
2007-04-01 |
탄소강 |
칠레ㅔ |
|
대구 |
2007-04-24 |
탄소강 |
아르헨티나 |
|
대구 |
2007-05-02 |
마그네슘 |
칠레 |
|
대구 |
2007-05-10 |
티탄 |
타이 |
|
인천 |
200-05-10 |
아연 |
미국 |
|
인천 |
2007-05-28 |
주석 |
러시아 |
COUNT함수가 인수로 쓸 수 있는 열은 한개밖에 없다. COUNT(material, orgland)라고는 쓸 수 없을 것이다. 어떻게 하면 될까? 한개밖에 인수로 쓸 수 없다면 강제로 인수를 한개로 만들면 될 것이다.
|
SELECT center
--결과-- CENTER
--EXISTS를 사용하기 |
|
select distinct center |
TestResults테이블을 이용해 아래 문제의 쿼리를 작성해보자.
TestResults
|
student_id |
class |
sex |
score |
|
001 |
A |
남 |
100 |
|
002 |
A |
여 |
100 |
|
003 |
A |
여 |
49 |
|
004 |
A |
남 |
30 |
|
005 |
B |
여 |
100 |
|
006 |
B |
남 |
92 |
|
007 |
B |
남 |
80 |
|
008 |
B |
남 |
80 |
|
009 |
B |
여 |
10 |
|
010 |
C |
남 |
92 |
|
011 |
C |
남 |
80 |
|
012 |
C |
여 |
21 |
|
013 |
D |
여 |
100 |
|
014 |
D |
여 |
0 |
|
015 |
D |
여 |
0 |
Q1.클래스의 75%이상의 학생이 80점이상인 클래스를 선택하시오
|
SELECT class THEN 1 ELSE 0 END);
--결과-- CLASS |
Q2.50점 이상을 받은 학생 중, 남자수가 여자수보다 많은 클래스를 선택하시오
|
SELECT class
--결과-- CLASS -------- B C |
Q3. 여자의 평균점이 남자의 평균점보다 높은 클래스를 선택하시오.
|
SELECT class
--결과-- CLASS ------- A |
아래 테이블을 이용해서 수학이 80점 이상이고 국어가 50점 이상인 학생을 찾는 쿼리를 작성해보자.
TestScores
|
student_id |
subject |
score |
|
100 |
수학 |
100 |
|
100 |
국어 |
80 |
|
100 |
과학 |
80 |
|
200 |
수학 |
80 |
|
200 |
국어 |
95 |
|
300 |
수학 |
40 |
|
300 |
국어 |
90 |
|
300 |
사회 |
55 |
|
400 |
수학 |
80 |
|
SELECT student_id
--결과-- STUDENT_ID |
HAVING구를 사용함에 있어 포인트를 한마디로 얘기하라면 "무엇으로 집합이라고 가정할 것인지에 착목하라"는 것이다. SQL에 있어서 무엇을 집합으로 가정할 것인지의 기준은 집합을 이루는 것이 현실세계에서 어떤 레벨인지는 상관없고, 단지 테이블에서 어떻게 표현되는지만이 중요하다. 어떤 실체가 때에 따라서는 요소가 되기도 하고 집합이 되기도 하는 것이다. 실체 한개당 한행만이 할당된다면 이 실체는 집합의 요소로써 취급되고 있는 것이다. 이때는 조건을 지정할 때 WHERE구를 사용하면 된다. 한편 한개당 복수행이 할당된다면 집합으로 취급되고있다는 증거이다. 그렇다면 HAVING구를 사용하면 된다.
집합의 성질을 조사하기 위한 대표적인 조건을 정리해두자. 이 조건은 HAVING구 혹은 SELECT구의 CASE식에서 사용할 수 있다.
집합의 성질을 찾기 위한 조건의 사용법 일람
|
|
조건식 |
용도 |
|
1 |
COUNT(DISTINCT col) = COUNT(col) |
col값이 유일하다 |
|
2 |
COUNT(*) = COUNT(col) |
col에 NULL이 존재하지 않는다 |
|
3 |
COUNT(*) = MAX(col) |
col는 결번이 없는 연번(개시값은 1) |
|
4 |
COUNT(*) = MAX(col) - MIN(col) + 1 |
col는 결번이 없는 연번(개시값은 임의의 정수) |
|
5 |
MIN(col) = MAX(col) |
col가 한개만의 값을 가지던가 아니면 NULL이다 |
|
6 |
MIN(col) * MAX(col) > 0 |
모든 col_x의 기호가 동일하다 |
|
7 |
MIN(col) * MAX(col) < 0 |
최대값은 양수고 최소값은 음수이다 |
|
8 |
MIN(ABS(col)) = 0 |
col은 적어도 한개의 0를 포함한다 |
|
9 |
MIN(col - 정수 ) = -MAX(col - 정수) |
col의 최대값과 최소값은 지정한 정수에서 값은 간격으로 떨어져있다 |
[출처] SQL _ HAVING_2|작성자 미우
'먹고살기 > Oracle' 카테고리의 다른 글
| SQL _ HAVING (0) | 2011.04.29 |
|---|---|
| SQL _ 상관서브쿼리 (0) | 2011.04.29 |
| SQL _ CASE식 (0) | 2011.04.29 |
| [Oracle] ROWNUM 사용 시 주의 (0) | 2011.04.25 |
| 오라클 데이터 타입 (0) | 2011.04.22 |
설정
트랙백
댓글
글
--단순CASE식--
CASE sex
WHEN '1' THEN '남'
WHEN '2' THEN '여'
ELSE '기타'
END
--검색CASE식--
CASE WHEN sex = '1' THEN '남'
WHEN sex = '2' THEN '여'
ELSE '기타' END
CASE식의 서식은 위와 같이 단순CASE식과 검색CASE식 두가지가 있다. 단순 CASE식은 이름 그대로 간결하게 쓸 수 있으나 비교조건 밖에 가능하지 못한 반면 검색 CASE식은 다양한 비교조건을 사용할 수 있다.
1.기존 코드체계를 새로운 체계로 변경하여 집계하기
PopTbl 집계결과
pref_name
population
지방명
인구
인천
100
경기
650
수원
200
→
경북
600
광명
150
기타
450
안양
200
대구
300
경주
100
포항
200
부산
400
제주
50
왼쪽 테이블의 도시별 인구를 집계하는 SQL을 만들어보자.
|
SELECT CASEpref_name
DISTRICT SUM(POPULATION) |
2.다른 조건의 집계를 하나의 SQL로 행하기
|
pref_name |
sex |
population |
지방명 |
남 |
여 | |
|
인천 |
1 |
60 |
인천 |
60 |
40 | |
|
인천 |
2 |
40 |
수원 |
100 |
100 | |
|
수원 |
1 |
100 |
광명 |
100 |
50 | |
|
수원 |
2 |
100 |
|
안양 |
100 |
100 |
|
광명 |
1 |
100 |
→ |
대구 |
100 |
200 |
|
광명 |
2 |
50 |
경주 |
20 |
80 | |
|
안양 |
1 |
100 |
포항 |
125 |
125 | |
|
안양 |
2 |
100 |
서울 |
250 |
150 | |
|
대구 |
1 |
100 |
||||
|
대구 |
2 |
200 |
||||
|
경주 |
1 |
20 |
||||
|
경주 |
2 |
80 |
||||
|
포항 |
1 |
125 |
||||
|
포항 |
2 |
125 |
||||
|
서울 |
1 |
250 |
||||
|
서울 |
2 |
150 |
|
|
SELECT pref_name,
PREF_NAME CNT_M CNT_F
|
3. 조건을 분지시킨 UPDATE
|
name |
salary |
|
영희 |
300000 |
|
순희 |
270000 |
|
민희 |
220000 |
|
원희 |
290000 |
위의 테이블에 대해, 다음과 같은 조건으로 변경시켜보자
1.현재의 급료가 30만이상인 사원은 10%삭감한다.
2.현재의 급료가 25만이상 28미만인 사원은 20%인상한다.
단순히 생각하면 다음과 같이 UPDATE문을 2번 실행하면 될 것 같지만 이는 맞지 않다.
|
--조건1. |
왜 이런 결과가 나올까? 예를 들어 현재 급료가 30만원인 사원의 경우 조건1의 UPDATE문에 의해 급료가 27만원으로 줄었다. 하지만 이것이 끝이 아니라 다음에 실행되는 조건2의 UPDATE문에 의해서 32만4000원으로 늘어나버리기 때문이다. 두가지 조건을 정확하게 반영하는 SQL문은 다음과 같다.
|
UPDATE Personnel |
위의 SQL뮨은 정확한데다 한번의 실행으로 해결되기 때문에 속도도 빨라진다.
4. 테이블 간의 매칭
DECODE함수등과 비료해서 CASE식의 최대 장점은 식을 평가가능하다는 것이다. 이말은 즉, CASE식 중에 BETWEEN,LIKE,<,>등을 사용할 수 있다는 말이다. 그 중에서도 IN 과EXISTS는 서브쿼리를 인수로 취하기 때문에 매우 강력한 표현력을 가진다.
CourseMaster OpenCourses
|
course_id |
course_name |
month |
course_id | |
|
1 |
피아노 |
200706 |
1 | |
|
2 |
태권도 |
200706 |
3 | |
|
3 |
미술 |
200706 |
4 | |
|
4 |
컴퓨터 |
200707 |
4 | |
|
200708 |
2 | |||
|
200708 |
4 | |||
위 테이블로 부터 다음과 같은 월별 개강 상태를 한눈에 알 수 있도록 표를 만들어보자.
|
COURSE_NAME 6월 7월 8월 |
이는 즉, OpenCourses의 어느 달에 CourseMaster테이블의 강좌가 존재하는지를 체크하는 것이다. 이 매칭의 조건을 CASE식으로 쓰는 것이 가능하다.
|
--IN 이용-- SELECT CM.course_name, --EXISTS 이용-- SELECT CM.course_name, |
IN 이나EXISTS 어느쪽을 써도 결과는 같지만 퍼포먼스면에서 EXISTS를 쓰는 편이 좋다. 서브쿼리에서 (month, course_id)라는 주키의 인덱스를 이용할 수 있기 때문에 특히나 OpenCourses테이블의 사이즈가 클 경우는 굉장히 우위에 서게 된다.
5.CASE식 중에 집약함수를 사용
|
std_id |
club_id |
club_name |
main_club_flg |
|
100 |
1 |
야구 |
Y |
|
100 |
2 |
기타 |
N |
|
200 |
2 |
기타 |
N |
|
200 |
3 |
배드민턴 |
Y |
|
200 |
4 |
축구 |
N |
|
300 |
4 |
축구 |
N |
|
400 |
5 |
수영 |
N |
|
500 |
6 |
바둑 |
N |
학생은 복수의 클럽에 소속되어있는 경우도 있으면 (100,200), 1개밖에 소속되지 않은 경우도 있다.(300,400,500). 복수의 클럽에 소속되어 있는 학생에 대해서는 주클럽이 어느것인지 나타내는 클럽열에 Y 혹은 N 의 값이 들어간다. 1개의 클럽에만 전념하는 학생은 N이 들어간다.
그럼, 위 테이블로부터 다음과 같은 조건으로 쿼리를 만든다.
1. 1개의 클럽에 소속된 학생에 대해서는 그 클럽의 ID를 취득한다.
2. 복수의 클럽에 소속된 학생에 대해서는 주요한 클럽의 ID를 취득한다.
단순히 생각하면 다음과 같은 두개의 조건에 대응하는 쿼리를 만들면 될 것이다.
|
--조건1 :1개의 클럽에 전념하는 학생을 선택-- select std_id, max(club_id) main_club
--조건2 : 복수 클럽에 소속되어 있는 학생을 선택-- select std_id, club_id main_club
|
이것으로도 조건에 만족하는 결과를 얻을 수 있지만 열에 의해 복수의 SQL이 필요하다. CASE식을 쓰면, 다음과 같은 한개의 SQL만으로 쓸 수 있다.
|
select std_id, STD_ID MAIN_CLUB |
CASE식 중에 집약함수를 써서, 거기다 그 안에 CASE식을 쓰는 어지러워보이는 네스트구조이지만 정리하자면 「한개 클럽에 전념하는가, 복수의 클럽에 소속되어 있는가」라는 조건분지를 CASE WHEN COUNT(*) _ 1 .....ELSE .....라는 CASE식으로 표현한 것이다. 이는 혁명적인 표현방법이다. 왜냐하면 우리가 처음 SQL입문을 배울 때 집계결과에 대한 조건은 HAVING구를 써서 설정한다고 배웠지만 CASE식을 쓰면 SELECT구에서도 동등 조건 분지를 쓸 수 있기 때문이다. 이 예문에서도 알 수 있듯이 CASE식은 SELECT구에서 집약함수 중에서도 밖에서도 쓸 수 있다. 이 자유도가 높은 점이 CASE식의 큰 매력이다.
------ 정리
SQL에서의 cASE식을 순차적언어의 CASE문에 연연해서 CASE「문」이라고 하는 경우가 있다. 하지만 정확히는 문이 아니라 1+1이나 a/b와 같은 식의 동료이다. 「문」과「식」의 차이는 기능의 방식의 차이를 반영하는 중요한 포이트이다. 식이기 때문에 CASE식은 실행시에는 평가되어져 하나의 값으로 결정되어지고 (그렇기 때문에 집약함수 중에 쓸 수 있다), 식이기 때문에 SELECT구에서도 GROUP BY구에서도 WHERE구에서도 ORDER BY구에서도 쓸 수 있는 것이다. 쉽게 말하면 CASE식은 열명이나 정수를 쓸 수 있는 장소에서는 언제든지 쓸 수 있다.
[출처] SQL _ CASE식|작성자 미우
'먹고살기 > Oracle' 카테고리의 다른 글
| SQL _ 상관서브쿼리 (0) | 2011.04.29 |
|---|---|
| SQL _ HAVING_2 (0) | 2011.04.29 |
| [Oracle] ROWNUM 사용 시 주의 (0) | 2011.04.25 |
| 오라클 데이터 타입 (0) | 2011.04.22 |
| 오라클 DECODE (0) | 2011.04.22 |
설정
트랙백
댓글
글
똑같은 query를 다른 두 시스템에서 실행했다. 헌데 그 결과는 완전 정반대.. 이런 어처구니 없는 경우가 있을 수가.. 아주 황당했다. (사실은 query가 바보였음 -ㅅ-)
(실제 테이블을 내용을 쓸 수 없으니 살짝 테이블 이름과 내용을 바꿔서..) 내가 원하는 결과는 사용자 테이블과 로그인한 시간, IP 등을 기록하는 테이블을 조인해서.. 가장 최근의 기록 1개를 얻고 싶다.
FROM (SELECT U.USER_ID, H.LOGIN_TIME, ROWNUM AS RNUM
FROM USER U, LOGIN_HIST H
WHERE U.USER_ID = H.USER_ID
ORDER BY H.LOGIN_TIME DESC
AND u.user_name = '바보') SUB
WHERE RNUM = 1;
자.. 이 query의 문제는 뭘까?? 사실 이 문제가 발생하기 전 까지는 누가 만들어 놓은건지도 궁금하지 않았던 저 구석에 있던 query인데.. 문제는 이렇게 발생했다. 다음은 동일한 데이터를 가진 두 서버에서 실행한 이 query의 결과이다.
USER_ID | LOGIN_TIME
--------+-----------
test1 | 2010-10-10 10:10:10
2번 서버
USER_ID | LOGIN_TIME
--------+-----------
test1 | 2010-10-05 10:10:10
왜 이런 결과가 나온걸까?? 우선 가장 바깥에 있는 select 문을 벗겨서 subquery 부분만 실행해 봤다. 그랬더니 이런 결과가 나오는 것이 아닌가??
USER_ID | LOGIN_TIME | RNUM
--------+------------+-----
test1 | 2010-10-10 10:10:10 | 1
test1 | 2010-10-09 10:10:10 | 2
test1 | 2010-10-07 10:10:10 | 3
test1 | 2010-10-05 10:10:10 | 4
2번 서버
USER_ID | LOGIN_TIME | RNUM
--------+------------+-----
test1 | 2010-10-10 10:10:10 | 4
test1 | 2010-10-09 10:10:10 | 3
test1 | 2010-10-07 10:10:10 | 2
test1 | 2010-10-05 10:10:10 | 1
아니!! 같은 query인데 RNUM이 정반대로 붙어있는게 아닌가?? 정말 귀신이 곡할 노릇이라고 하면서 검색을 시작.. 흠.. 검색 시작한지 2분도 안돼서 답 발견 @ㅅ@
역시 문제는 ROWNUM이었다. ROWNUM의 동작 원리를 알지 못 한 상태에서 query를 만드니 저런 query가 만들어진 것 같다. 일단, ROWNUM은 select된 결과 집합에 대한 가상 순번이다. 이 번호는 DB에서 꺼내지는 순서대로 붙게 된다. (optimizer가 어떻게 동작하는지에 따라 그 순서는 달라질 수 있다.) 그리고 결정적으로 잘못 생각한 것은 ORDER BY 구문.. ORDER BY는 결과 집합이 생성된 후에 적용되는 조건이다.
이 두 동작 원리를 가지고 다시 문제를 짚어보자. 내가 원하는 것은 해당 이름의 사용자가 가장 최근에 로그인한 시간을 알고 싶은 것이다. 다시 말해 먼저 로그인한 시간으로 정렬한 후 번호를 붙여서 가장 최근 정보를 가져오는 순서다. 헌데.. ROWNUM과 ORDER BY를 하나의 SELECT문에 넣게 되면서 그 적용 순서가 의도와는 다르게 뒤바뀌게 된 것이다. 결과 집합을 꺼내오면서 ROWNUM이 먼저 적용되고, 모든 결과 집합이 모인 후에 정렬이 된 것이다. 오라클의 optimizer가 동작하는 경우에 따라서 결과 집합을 만드는 순서가 바뀔 수 있고 위의 두 서버와 같이 정반대의 결과가 나올 수도 있는 것이다.
사실 이 query는 이런 원리를 알고 보면 다음과 같이 수정해면 간단하게 원하는 결과를 얻을 수 있는 것이다. 처음부터 왜 저렇게 ROWNUM을 붙였는지 잘 모르게뜸 @ㅅ@
FROM (SELECT U.USER_ID, H.LOGIN_TIME
--, ROWNUM AS RNUM 이 분분은 사실 필요 없기 때문에 제거
FROM USER U, LOGIN_HIST H
WHERE U.USER_ID = H.USER_ID
ORDER BY H.LOGIN_TIME DESC
AND u.user_name = '바보') SUB
WHERE ROWNUM = 1;
'먹고살기 > Oracle' 카테고리의 다른 글
| SQL _ HAVING_2 (0) | 2011.04.29 |
|---|---|
| SQL _ CASE식 (0) | 2011.04.29 |
| 오라클 데이터 타입 (0) | 2011.04.22 |
| 오라클 DECODE (0) | 2011.04.22 |
| 인덱스의 정의 (0) | 2011.04.22 |
설정
트랙백
댓글
글
|
이 름 |
최대 길이 |
타 입 |
설 명 |
|---|---|---|---|
|
CHAR |
2000 byte |
문자열 |
고정 길이 |
|
NCHAR |
2000 byte |
문자열 |
다국적 언어 지원 |
|
VARCHAR2 |
4000 byte |
문자열 |
가변 길이 |
|
NVARCHAR2 |
4000 byte |
문자열 |
가변 길이, 다국적 언어 지원 |
|
LONG |
2 Gb |
문자열 |
가변 길이 |
|
RAW |
2 Gb |
바이트 문자열 |
가변 길이 |
|
LONG RAW |
2 Gb |
이진 문자열 |
|
|
NUMBER |
10^-38 ~ 10^38 |
숫자 |
|
|
DATE |
날짜 |
BC 4712/1/1 ~ CE 4712/12/31 | |
|
BLOB |
4 Gb |
이진 데이터 |
구조화 되지 않은 데이터 |
|
CLOB |
4 Gb |
문자 데이터 |
구조화 되지 않은 데이터 |
|
NCLOB |
4 Gb |
문자 데이터 |
다국적 언어 지원 |
|
BFILE |
4 Gb |
이진 데이터 |
데이터베이스 외부에 데이터를 저장함 |
|
ROWID |
10 byte |
이진 데이터 |
로우 어드레스 |
|
ROWID |
4000 byte |
이진 데이터 |
로우 어드레스 |
ANSI/ISO SQL 타입과의 비교
|
ANSI/ISO SQL 데이터 타입 |
오라클 데이터 타입 |
|---|---|
|
CHARACTER(n), CHAR(n) |
CHAR(n) |
|
NUMERIC(p,s), DECIMAL(p,s), DEC(p,s) |
NUMBER(p,s) |
|
INTEGER, INT, SMALLINT |
NUMBER(38) |
|
FLOAT(p) |
FLOAT(p), NUMBER |
|
REAL |
FLOAT(63), NUMBER |
|
DOUBLE PRECISION |
FLOAT(126), NUMBER |
|
CHARACTER VARYING(n), CHAR VARYING(n) |
VARCHAR2(n) |
SQL/DS, DB2 데이터 타입과 비교
|
SQL/DS, DB2 데이터 타입 |
오라클 데이터 타입 |
|---|---|
|
CHARACTER(n) |
CAHR(n) |
|
VARCHAR(n) |
VARCHAR2(n) |
|
LONG VARCHAR |
LONG |
|
DECIMAL(p,s) |
NUMBER(p,s) |
|
INTEGER, SMALLINT |
NUMBER(38) |
|
FLOAT(p) |
FLOAT(p), NUMBER |
|
DATE |
DATE |
SQL/DS, DB2 데이터 타입 중 TIME, TIMESTAMP, GRAPHIC, VARGRAPHIC, LONG VARGRAPHIC들은
오라클 데이터 타입과 대칭되는 것이 없다.
[출처] 오라클 데이터 타입|작성자 하늘아이
'먹고살기 > Oracle' 카테고리의 다른 글
| SQL _ CASE식 (0) | 2011.04.29 |
|---|---|
| [Oracle] ROWNUM 사용 시 주의 (0) | 2011.04.25 |
| 오라클 DECODE (0) | 2011.04.22 |
| 인덱스의 정의 (0) | 2011.04.22 |
| [ORACLE] 데이터베이스 시작의 3단계 설명 (0) | 2011.04.22 |
설정
트랙백
댓글
글
DECODE
프로그래밍언어의 스위치 문과 같은 기능을 하는 SQL 함수이다.
- 형식
|
DECODE (비교값 , CASE1 , 결과 1 , CASE2 , 결과 2 , CASE3 , 결과 3..... , 기본값)
|
- 주의사항
비교값 과 CASE 값의 데이터 타입이 같아야 한다.
다를 경우에는 자동형변환이 되면 문제없지만 자동형변환이 불가능할 경우 오류를 발생한다.
※ 오라클이 알아서 비교값을 CASE 값과 같은 타입으로 변환시키려고 시도한다.
※ DECODE함수
- 특정 컬럼의 값을 기준으로 마치 IF문을 사용하는 것과 같은 효과를 내는 함수
- 해당 컬럼의 값이 'A'이면 지정한 특정한 값을 출력하고, 'B'이면 또 다른 값을 출력
- 기본값을 정해서 조건을 만족하지 않는 경우의 출력 제어 가능
- 구문
DECODE({column | expression}, search1, result1 [,search2,result2] ...
[,default] )
- 사용 예
① job값에 따른 새로운 직업명 출력
② deptno에 따른 인상급여 출력
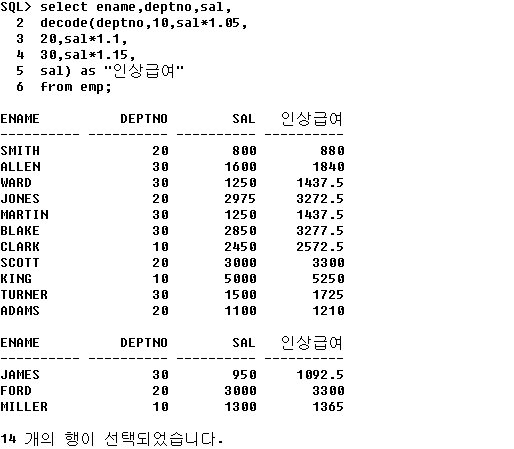
[출처] 오라클 DECODE|작성자 하늘아이
'먹고살기 > Oracle' 카테고리의 다른 글
| [Oracle] ROWNUM 사용 시 주의 (0) | 2011.04.25 |
|---|---|
| 오라클 데이터 타입 (0) | 2011.04.22 |
| 인덱스의 정의 (0) | 2011.04.22 |
| [ORACLE] 데이터베이스 시작의 3단계 설명 (0) | 2011.04.22 |
| 오라클 변환함수 ( TO_CHAR ) (0) | 2011.04.22 |
RECENT COMMENT